So if you’ve paid any attention to news about the internet in the last thirty years you’ve probably heard that we’re going to imminently run out of IPv4 addresses, like, any day now. Various groups have been saying this since the 90’s, with RFCs describing the problem and everything. So why aren’t single IPv4 addresses the world’s most expensive numbers? Why are us lowly consumers allowed the luxury of having our very own hyper-scarce IPv4 address just for our house!? Let’s take a look.
A crash-course on IPv4 and it’s scarcity
Back in the good old days of 1981, RFC 791 was released, which essentially defines IPv4 as a concept. They can’t really be blamed for it, but the authors of this RFC made the classic mistake of finding a number of proposed addresses significantly larger than what they could imagine and said - surely that’ll be enough! IPv4 uses a 32-bit numbering scheme, which means that there are 4,294,967,296 (232) possible addresses, less about 288 million for multicast and private networking (e.g. 192.168.x.x), as per defined in the spec, and less some more which are reserved by the various global number authorities (somewhere in the range of about 550 million).
Now an important concept to understand here, is that the thinking for internet architecture was quite different then to what it is today. In 1981, computing equipment was firmly still in the hands of businesses and universities - any kind of consumer networking (let alone the WWW) was about 5-6 years off yet, and even if they foresaw that, what they were really thinking was perhaps a family might have one computer, just as they might have one television. The existing comparison was the telephone network, where the scope of addresses (phone numbers) rarely was more granular than a single physical address. In rare instances, a household might have two phone numbers - in which case, you were certainly the coolest kid on the block. The only places that had complex phone systems with lots of numbers at a physical address, were businesses and universities. We’ll come back to this phone analogy later.
As such, early internet architecture thinking1, was to give every device on the internet their own IP address, so that every single internet device could reach every other. This principle is known as true end-to-end connectivity. Using the phone system as an exemplar, and trying to build your system to be as flexible for any use-case as possible, this makes a lot of sense.
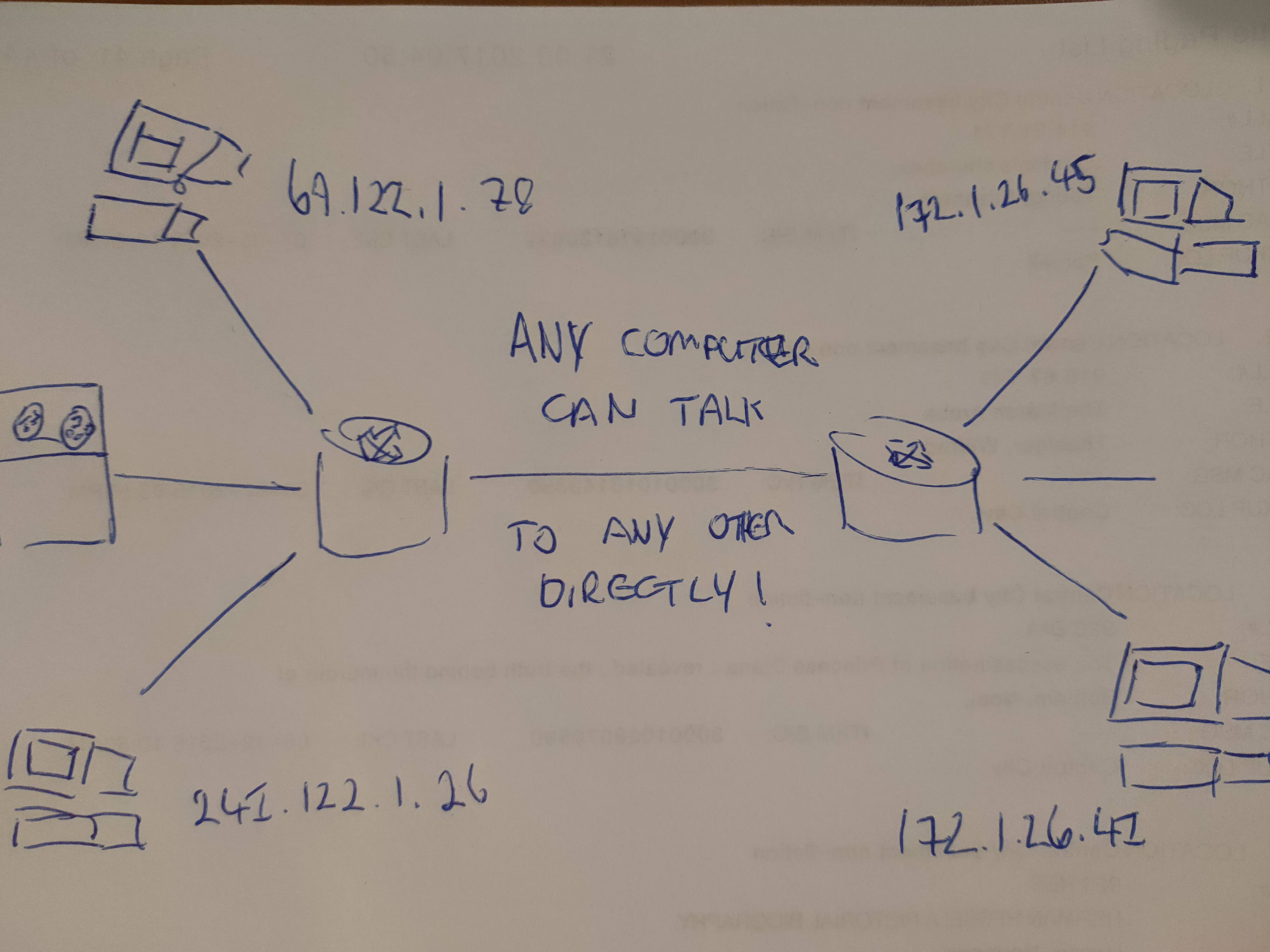
Figure 1: How the ARPANET designers of old thought the internet would work
In 1989, Tim Berners-Lee writes the world-changing Hyper-text Transfer Protocol (HTTP), and Hyper-Text Markup Language (HTML) to go along with it. Building on-top of existing internet infrastructure, Hyper-text allows the internet to explode. Coupled with rapidly decreasing costs for hardware, internet access enters the domain of consumers in the mid to late 90’s. Still following this concept of ‘every device gets an IP’, IP address consumption rapidly increases.
In January of 2011, IANA gave out the last /8. It depends on how you draw the lines, but technically speaking this meant every last bit of IPv4 address space that wasn’t reserved had been given out to the various local number authorities. Subsequently, these number authorities began to run out of what they had, and this resulted in news story after news story of “then end of IPv4”, which never actually eventuated. That’s not quite true to say - the problems are there, but the fires are rapidly being put out.

A timeline of IPv4 Exhuastion. Michel Bakni - CC-BY-SA-4.0
By as early as 1992, long before we actually ‘ran out’, the alarm bells were ringing, and those helping to set internet standards needed to find solutions. Thus enters the primary solution, Network Address Translation, or NAT for short.
How to fight an IP fire: NAT and IPv6
Network Address Translation is a neat little tool where a router assumes the role of the ‘one’ computer/internet endpoint in your house or business, and translates connections from the internet into the private network by knowing what data should go where usually based on port number. This is functionality equivalent to PBXs in large business phone systems, where extension numbers are used to reach the desired person. Functionally, this means you only need one ‘public’ facing IP address to have up to 65,535 thousand internal computers. This vastly increases the pool of computers that can access the internet, with IPv4 as the core backbone addressing scheme. The theoretical max here is 281,474,976,710,656 (281 trillion) connections. Pales in comparison to IPv6, but still.
NAT has become wildly popular for several reasons:
- It beat IPv6 to the punch
- Implementation of NAT was possible without completely changing out the backbone of the internet, which mean that businesses could just implement it in their own time
- Legacy devices, though inefficient, were still supported. There were a lot more of these in 1994 when NAT was proposed
- It provides a veil of security
- More recently, it’s one of the major ways we load-balance. This one is really important, and we’ll come back to it later
Point 2 is really the core reason NAT reached the popularity it has. It was simply cheaper and easier than a complete network stack rebuild, to just extend IPv4. This is another example of taking the easier way out and building complexity on top of it to mitigate the shortcomings of this approach, which we see everywhere in systems design in general.
While IPv4 provided what was intended to be an interim solution to the problem, IPv6 was supposed to solve it. IPv6 is a really really smart addressing scheme that has many benefits I won’t go over here, but essentially the main thing is that it’s addressable pool is 2128 (340 undecillion). This, at risk of making another “surely that’ll be enough” moment, is a lot of addresses.
Why isn’t IPv6 our knight in shining armor?
Well, it is, but IPv6 uptake has been slow, and this is critically related to point 2 of why NAT became popular. Because it costs a lot of money to change over. You typically need new hardware, extensive network infrastructure changes, a lot of testing, and you need your ISP and your customers to support it for a complete IPv6 to IPv6 communication train. It’s a critical mass thing - once most of your customers or target audience can communicate with IPv6 and it’s equal cost or cheaper to do so, you’ll switch to IPv6, but never before that. Any sane business won’t commit unless it truly believes it will see some commercial benefit from doing it, and that’s hard to justify when IPv4 w/ NAT is mostly still affordable and ‘works just fine’.
In my opinion, we won’t see a critical mass quickly until it becomes financially undesirable to maintain an exclusively IPv4 infrastructure. One proposed solution here, is an IPv4 marketplace where IPv4 addresses become a tradable good akin to shares. This is essentially throwing capitalist free-market economics at the problem, which in this instance I actually support. To some extent scarcity has been reflected in the prices of IPv4 addressing, but perhaps not to the extent that it would be in a free market, where in theory we’ll see the true capital value of the scarcity of IPv4. Assuming we see significant price rises, at some point it will become economic to switch to IPv6 to save cost. From a functional perspective, an ISP could fairly easily do this without consumers noticing, especially with the type of customer on CGNAT and cellular plans, which rarely if ever need true E2E connectivity. Joe Bloggs who only ever goes to rnz.co.nz and XTRA mail aint gonna notice his IP address is now 2001:db8::8a2e:370:7334 instead of 172.112.23.211.
The major risk to IPv6
However, the concern here is that we might not see that rise in cost. This might be because the architecture of the internet has changed to a point where we don’t need E2E connectivity as a principle. Let’s come back to NAT and point 5, about load-balancing. The internet today is a very different place architecturally to 1981, where we had this concept of E2E connectivity. This was based on the assumption that the vast majority of communication would be of a purely distributed peer-to-peer nature. Anyone who has files or services they want to host, would host it on their own machine at their own location. In modern terms, this would be like if you wanted to visit rnz.co.nz, and they had a webserver in their basement that you’d connect to directly, regardless of where in the world you are.
However, what we see today is a client-server based internet. We have lots of consumers who host no content themselves, only consume, and several massive CDN networks (Cloudflare, Akamai, etc.) that geographically duplicate resources and distribute it at scale. Instead of rnz.co.nz hosting their website in their basement, they actually host it with Amazon, who has a worldwide CDN network. We here in NZ connect to Syndey, and someone in Europe connects to somewhere in France. There are millions of web resources that aren’t like this, but by sheer volume of traffic, these CDNs dominate. Using the client-server model, these limited number of CDNs have a small number of public IPs that they then load-balance using NAT into extensive internal virtual networks. The number of ‘webservers’ hasn’t actually changed, but CDNs aggregate these into immense virtual network trees all with private internal addressing. This means we can have thousands of distinct websites all accessible via six IPs, with a different one provided depending where in the world you are2.
If you want to host anything, it’s just easier, or perhaps the only option, via a convenient CDN service, such as Amazon’s AWS. At an even higher abstraction level, you can host your site through something like Squarespace or Google Sites. This accelerates this architectural trend. As I mentioned before - these consumers don’t care what their IP address is, so long as they can reach the content. This allows techniques such as CGNAT3 to reduce IP load on ISPs. What we get here is a resulting architecture where with CGNAT, GeoIP, and NAT load-balancing, you can theoretically connect up to 4.29 billion devices to 65 thousand unique services, local to them, with just two actual publicly routable IPv4 addresses.
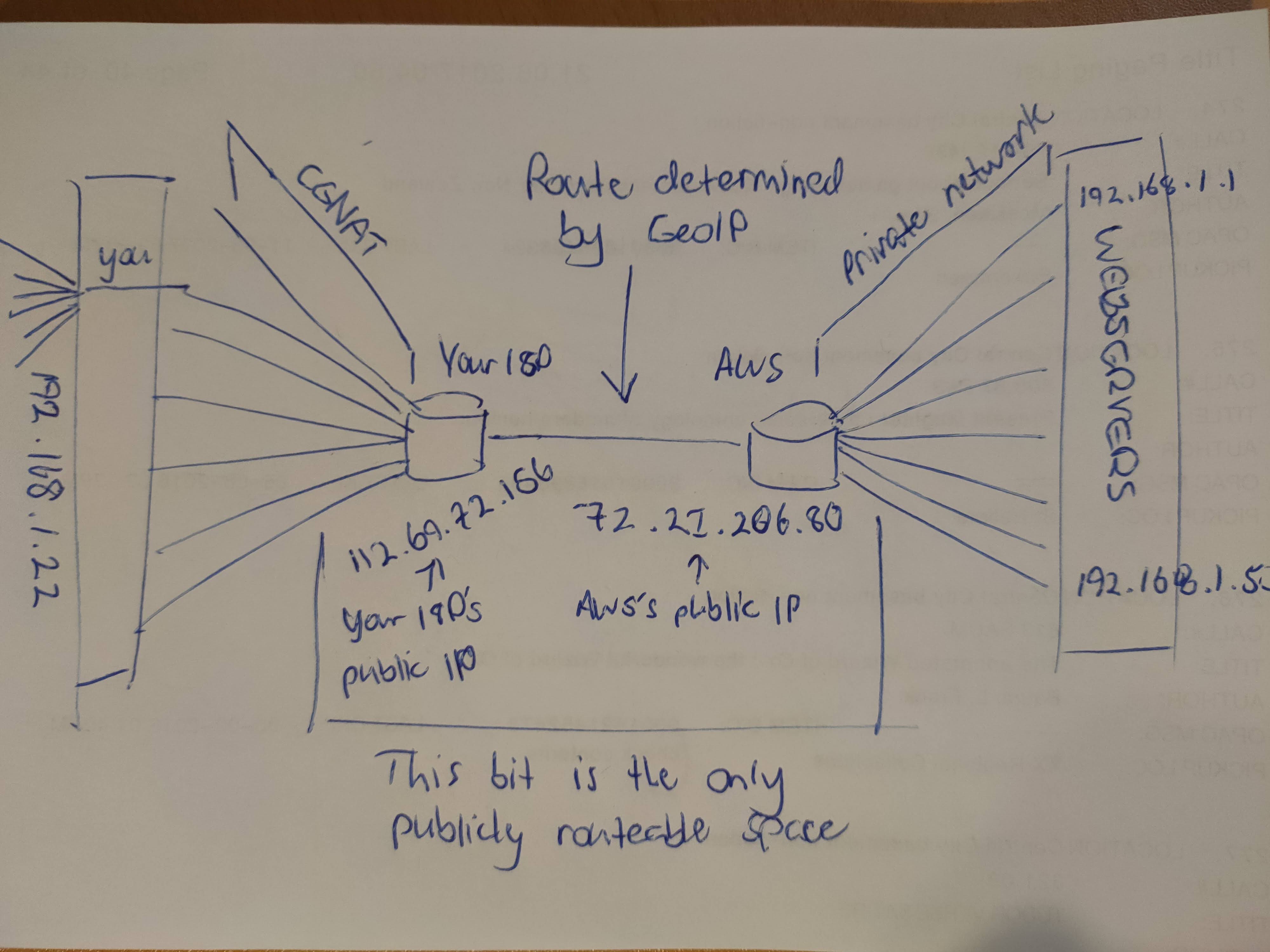
Figure 2: A snapshot of what the internet mostly looks like today
If this architectural trend continues, it may be so that we just don’t have a need to change to IPv6, because IPv4 meets the needs of this internet structure, and this would be reflected in our IPv4 marketplace. Geoff Huston, who writes an article for APNIC on this topic, discusses the point that this could be what prevents mainstream adoption of IPv6, as “the technology drivers for IPv6 related to IPv4 address exhaustion are lessening in their criticality, and the service environments that continue to operate in an IPv4-only mode are not suffering an adverse reaction from the market”.
Personally, I think this would be a great tragedy. IPv6 is just such a forward thinking protocol, and would, if you wanted to, re-enable this concept of E2E connectivity for the internet, especially for enthusiasts such as myself who could easily afford more public IPs than I could ever hope to use. Additionally, this trend of a CDN-based internet structure poses a risk in centralization. Yes, there are benefits to centralization, this has enormously contributed to stable web experiences, and dramatically reduces security risks when Amazon needs to be absolutely on the ball to be trustworthy. But, what happens if AWS goes down, when such an enormous amount of the internet’s services rely on it, even if the webservers themselves aren’t entirely within AWS. Azure, Akamai, Cloudflare, etc. are enormous organizations that are a large part of the backbone of the internet volume-wise, but they aren’t immune to terroisim, hacking, or the law. The more we pile on to these centralized locations, it means that when (not if) they do go down in a really big way we’ll see catastrophic levels of general failure. These things often go in cycles, so we may in fact soon return to decentralization to, among other things, reduce cost as CDN providers raise fees. When that happens, we want to be well and truly on IPv6.

If you have the choice to migrate to IPv6, do it. If you can pester your ISP to bring IPv6 support, do it. If you work in an ISP, and make decisions about whether to implement IPv6, please do it. We really need to get there, and at this stage, it’s looking a little too close for comfort.
Footnotes
- It may seem a little short-sighted but a key thing to understand is that these protocols were actually written for something called ARPANET. ARPANET was perhaps the forerunner to the internet, which was a WAN established between research institutes around the US. Almost all of our core internet protocols (TCP/IP primarily) were created in this environment, and it was reasonable to assume that this would really only ever span the universities of the US. In which case, 232 addresses is damn-well more than enough. When the internet came along, all of these protocols were just ported across irregardless of the technical debt this inherited - which is a really common thing to do (see Y2K).
- This functionality is provided by GeoIP routing, which is achieved through DNS. When you query a DNS record, the DNS server, if allowed, may query your location via GeoIP databases, and provide you the IP of a load-balancer or direct webserver local to you. This is intended to reduce latency by directing you to your closest CDN node. This can be used as an alternative to NAT-based load-balancing, or in combination with. Most major CDNs world wide use a combination, where you GeoIP’ed to your local hub, and then you get load-balanced via NAT to a final server.
- CGNAT, or Carrier-grade NAT, is a technique where ISPs put their customers behind their own NAT cones, which are then double-natted again once it reaches the local customers network through their router. This means the customer’s router sees a private IP address, and not a publicly routable one. This basically eliminates any possibility of the consumer ever hosting a discoverable service visible from the internet, as every connection that travels backwards through the CGNAT cone needs to have been established from the consumer’s side. This, by design, accentuates this scenario where using a CDN-based webservice might be the only option for some.